


Chapter 7 Implementation Repository (IMR)
7.1 Introduction
The CORBA specification briefly describes the concept of an implementation repository (IMR). This term is not very intuitive so it can benefit from an explanation. Implementation is the CORBA terminology for “server application”, and repository means a persistent storage area, such as a database or a file. This suggests that an implementation repository is a database/file that stores information about CORBA server applications. This is almost correct. An IMR usually also contains a CORBA server “wrapper” around the database/file, which makes it possible for CORBA applications to communicate with an IMR.
An IMR typically maintains the following information about each server application:
- A logical name that uniquely identifies a server, for example, “BankSrv” or “StockControlSrv”.
- A command that the IMR can execute to (re)start the server process.
- Status information that indicates whether or not the server is currently running; if the server is currently running then the IMR also records the host and port on which the server process listens.
The CORBA specification provides only a partial definition of an IMR. In particular, CORBA states the high-level functionality that an IMR should provide, but does not state how this functionality should be implemented. Neither does the specification state how the IMR should be administered. The need for a partial specification is because much of the functionality of an IMR must be implemented and administered in a platform-specific manner. For example:
- An IMR should be capable of starting and stopping a server process. Different operating systems have different ways of starting and stopping processes.
- An IMR should record details of servers—such as the command used to launch a server—and whether or not the server is currently running. Some IMRs may store this information in a database. Other IMRs might record this information in a textual file. An IMR running on an embedded device might not have access to a file system or a database and hence might record server details in non-volatile RAM.
An IMR running on a mainframe would not only be implemented differently to an IMR running on a PC or an embedded device, it would also be administered differently. Put simply, one CORBA vendor’s IMR running on one kind of computer might have a very different “look and feel” to another CORBA vendor’s IMR running on a different kind of computer. This wide variation in IMRs is the reason why the CORBA specification contains only a high-level discussion about IMRs.
Section 7.2 illustrates the principles of an IMR through an example that is based on a hypothetical CORBA implementation. Then Section 7.3 outlines the IMRs of three different CORBA products. In this way, I illustrate how some of the details of an IMR vary from one product to another but the basic principles remain the same.
7.2 IMR Concepts
7.2.1 Registering a Server with the IMR
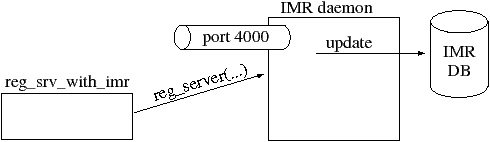
An IMR is typically implemented as a CORBA server “wrapper” around a database/file that persistently stores details of servers that have been registered with the IMR. CORBA products usually provide a command-line utility that can be used to register a server application with the IMR. Such a utility might be used as shown below (the "\" character indicates a line continuation):
reg_srv_with_imr BankSrv \ -launch "/bin/bank_srv -ORBServerId BankSrv ..."
This utility takes details of a server application—such as a name (“BankSrv” in the above example) and its launch command—and somehow communicates this information to the IMR, which then persists the information in its database, as shown in Figure 7.1. Communication between the reg_srv_with_imr utility and the IMR is typically achieved by having this utility act as a CORBA client to the IMR. The IMR server process typically listens on a fixed port (shown as port 4000 in Figure 7.1). However, as mentioned in Section 7.1, the implementation details of the IMR are not standardized by CORBA, so the name of the reg_srv_with_imr utility, its command-line options, and how it communicates with the IMR vary from one CORBA product to another. Some CORBA products may provide a GUI administration program for registering servers instead of command-line utilities.
The launch command specified by reg_srv_with_imr contains
a pair of -ORBServerId <name> command-line arguments. Later,
when the IMR launches the server, this pair of command-line arguments
will be inspected by the server’s call to ORB_init()
(Section 3.2.3) and this instructs the server
process that it should identify itself to the IMR with the specified
name. Note that the latest CORBA specification (3.0) defines the
-ORBServerId <name> command-line option. Products that implement
an older version of the CORBA specification might use a different
command-line option to specify a unique name that identifies a server
to the IMR.
7.2.2 Manually Running a Server
Having registered the server with the IMR, you can now run the server manually, for example:
/bin/bank_srv -ORBServerId BankSrv ...
Note that when you run the server manually, you use the -ORBServerId BankSrv command-line option that was specified in the launch command when previously registering the server with the IMR. Figure 7.2 illustrates what happens when the server runs.
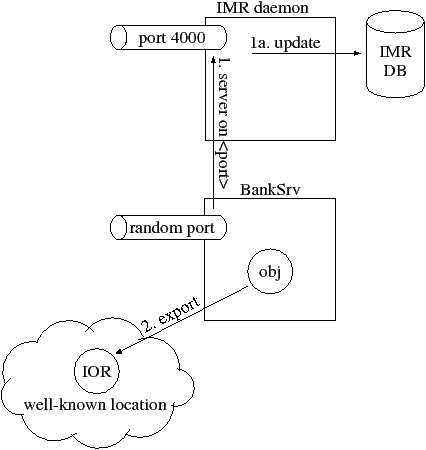
By default, the server listens on any available port, which is often called a random port.1 One of the CORBA APIs that is invoked during initialization of a server—typically ORB_init() or create_POA()2pt—informs the IMR that the server specified by the -ORBServerId command-line option is running and on which port it is listening (step 1). The IMR updates its database with the supplied details (step 1a). This communication between the server and the IMR is an implementation detail of one of the CORBA APIs that is invoked during server initialization. This means that the server-IMR communication is transparent to server developers.
An IMR somehow determines when a server terminates—so that the IMR can then record in its database the fact that the server is no longer running. CORBA has not standardized on the technique used by the IMR to determine when a server has terminated, but I briefly mention some of the techniques used by CORBA products. Some products have an undocumented object in the CORBA runtime system of servers and the IMR sends periodic “ping” messages to this to check if the server is still alive. Some other CORBA products open a socket/pipe connection between the IMR and a server; when the server terminates, the operating system automatically informs the IMR that the socket/pipe is being closed.
As part of a server’s initialization, it is likely that the server will export an object reference (step 2) to a well-known location. Indeed, client applications will use an object reference to communicate with a server, so it is important to manually run a server once (so that it can export an object reference) before clients try to communicate with the server. The means by which the server exports the object reference—for example, to a file (Section 3.4.2), the Naming Service (Chapter 4) or the Trading Service (Chapter 20)—are irrelevant to the present discussion.
An object reference (Chapter 10) contains the “contact details” for an object. When a server is deployed through an IMR then its exported (persistent) IORs specify how the object can be contacted through the IMR.2 In particular, the (host, port, object-key) information within the IOR might be as follows:
host: <IMR’s host>
port: 4000 (that is, the IMR’s port)
object key: “BankSrv”, <poa name>, <object id>
The object key in an IOR uniquely identifies an object within a server process. Within a server process, objects are grouped into collections called POAs (Section 5.5), and one server may contain several POAs. Because of this, the object key contains the name of the POA in which the object resides, and also the object id that uniquely identifies the object within its POA. What surprises some people is that (in many CORBA products) the object key within an IOR contains the logical server name, for example “BankSrv”. The reason for this is that (as shall be discussed in the next subsection) the IMR needs be able to examine the object key and determine in which server the object resides, so the IMR can redirect client requests to the appropriate server. Embedding the server’s name inside the object key information of an IOR is the most obvious way to link the object key to the corresponding server.3 If (something akin to) the server name was not present in the object key then the IMR would know only to which POA an object belonged. In such a case, for the IMR to have the ability to redirect a client’s request to the appropriate server would require that every persistent POA in every server be registered with the IMR, which would be a slight administrative burden. More importantly, it would make it impossible for several server applications that happened to have similarly-named POAs to be deployed through the same IMR, because there would be no way for the IMR to determine to which server an object belongs.4
7.2.3 Client Interaction with a Server and the IMR
Figure 7.3 shows what occurs when a client establishes communication with an object in a server. The client imports an IOR (step 1) from a well-known location. The first time the client tries to make a remote call to the object, it opens a socket connection to the host and port specified in the IOR. In our example, the host and port happen to be those for the server’s IMR rather than for the server itself, but the client process is not aware of this. The client sends its request (step 2). In the header of each request is the object key information from the IOR. When the IMR receives the request, it realizes that the object key does not match one of its own objects so, the IMR extracts the server name (“BankSrv”) from the object key and uses this to query its database (step 2a) for details of the server.
- If the database details indicate that the server is already running then the IMR obtains the server’s host and port from the database, constructs a new IOR based on the (host, port, object key) details, and sends back a redirection message to the client that contains this new IOR (step 3).
- If the database details indicate that the server is not currently running then the IMR obtains the server’s launch command from the database and uses this to (re)start the server (step 2b). The IMR then waits for the server to initialize itself and notify the IMR of its (probably random) port (step 2c). The IMR then updates its database with the server’s “currently running” status and port number. It then constructs a new IOR based on the (host, port, object key) details, and sends back a redirection message to the client that contains this new IOR (step 3).
The redirection message (Section 11.4) tells the CORBA runtime system in the client “The object you are looking for is not at this location, but here is a new IOR that tells you how to contact the object”. The CORBA runtime system in the client then opens a new socket connection to the host and port specified in the “redirection IOR” and resends its request (step 4). This “resend” logic is handled by the CORBA runtime system in the client—it is transparent to the application-level code in the client.
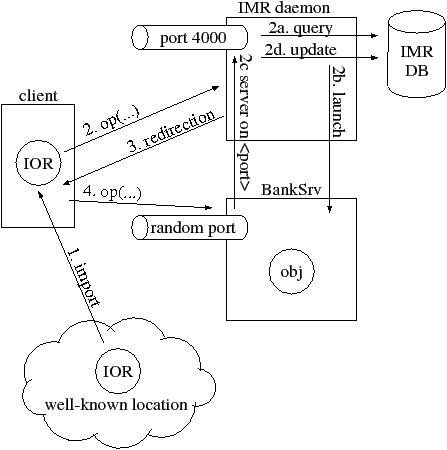
There are a few important points to note about the client initially talking to the IMR and then being redirected to the “real” server:
- The redirection occurs for just the first invocation from the client to an object. Subsequent requests from the client go directly to the “real” server. Because of this, any overheads associated with the redirection mechanism occur only during the initial connection establishment. Even for this redirection during the connection establishment, there is an optimization used in many CORBA products that avoids retransmission of large messages (Section 11.4).
- The redirection mechanism means that CORBA servers do not have to be pre-started. Instead, servers that have been registered with an IMR can be started on an “as needed” basis by the IMR. Also, only the IMR needs to listen on a fixed port (which is usually specified in a configuration file)—servers that are deployed through the IMR can listen on random ports, which is often convenient.
- The redirection mechanism is defined as part of the CORBA specification. Because of this, use of an IMR does not affect interoperability between a client built with one CORBA product and a server built with a different CORBA product. However, the means of interaction between the server and its IMR varies from one CORBA product to another. A practical effect of this is that an Orbix IMR can launch only Orbix servers, a TAO IMR can launch only TAO servers and so on.
- Let us assume that a client is redirected via the IMR to the server and that the client successfully makes several invocations upon the object in the server. If the server later terminates, thus causing the client to lose its connection to the server, then the CORBA runtime system in the client will automatically revert to using the host and port in the original IOR. This means that the client will send its next request to the IMR, which gives the IMR a chance to restart the server and redirect the client to the newly relaunched server.
- Some CORBA products allow you to register a replicated server with the IMR. For example, there might be 5 servers that all share the same logical server name of “BankSrv”. In such a CORBA product, the IMR could redirect some clients to one server replica, some more clients to another server replica and so on. This provides a per-client load-balancing mechanism, without the need for developers to explicitly add load-balancing logic to their applications. However, if you have a replicated server then it is your responsibility to ensure that the replicas do not suffer from cache inconsistency problems.
- It is possible to deploy a server without an IMR. In this case, an exported IOR contains the host and port of the server, so the client is not redirected through the IMR.
An IMR launches a server process by using operating system APIs to create a new process—for example, CreateProcess() on Windows or fork() and exec() on UNIX. On most operating system, such APIs can be used to create a new process on the same machine only, that is, they cannot be used to create a new process on a different machine. This suggests that you would need to have a separate IMR on each machine where you wish to launch server processes. This was a common feature of many early CORBA products. It resulted in some frustration for administrators of large CORBA deployments because they had to perform administration for several IMRs rather than than for just one IMR.
7.2.4 Distributed Implementation Repositories
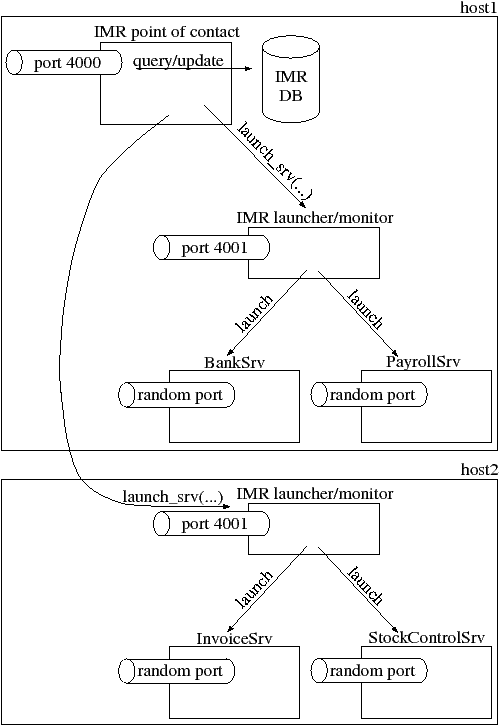
Many of the modern CORBA products have split the IMR into two parts, as shown in Figure 7.4. One process (called the “IMR point of contact” in the diagram) listens on a fixed port, for example, port 4000, and this port number is embedded in IORs for objects in servers that are deployed through the IMR. Aside from providing the well-known port to be embedded in IORs, this process is also typically used to perform queries and updates to the IMR database. Whenever the IMR wants to launch a server process, it delegates this responsibility to a second process—called the “IMR launcher/monitor” in Figure 7.4—that listens on another fixed port.
The intention of splitting the IMR functionality into two components is that there may be several “IMR launcher/monitor” processes—typically one for each computer on which server processes can be started. This arrangement allows an IMR to span several computers. Obviously, the utility for registering a server with the IMR needs to specify the host on which a server process will run, as shown in the example below (the "\" character indicates a line continuation):
reg_srv_with_imr BankSrv -host pizza.acme.com \ -launch "/bin/bank_srv -ORBServerId BankSrv ..."
One benefit of such a distributed IMR is that one centralized IMR database can be used to maintain the registration details of CORBA servers on several computers. Some organizations find this to be more convenient than having a separate IMR database for each computer.
Another benefit is that the host and port information in an IOR is always that of the “IMR point of contact” process, regardless of which host is used to run the server process. For example, the “BankSrv” might initially be run on one computer, but if this computer needs to undergo some maintenance work then the “BankSrv” can be stopped and re-registered/restarted on a different computer. In effect, the “BankSrv” can be migrated from one computer to another. This migration can take place without invalidating any previously exported IORs of the server, because the host information in the IORs remains that of the IMR’s point of contact process.
This distributed IMR architecture also offers a benefit for CORBA vendors. Much of the platform-specific code in an IMR is concerned with starting and stopping server processes. This platform-specific code can be encapsulated in the “IMR launcher/monitor” process, which enhances maintainability of the source code of the IMR.
Variations of the “distributed IMR” described above can be found in some modern CORBA products. The differences tend to concern the organization of the IMR database. For example:
- The “IMR point of contact” process might maintain a database that contains the rarely-changing, server registration details, such as a server’s logical name, launch command and host. Details of which servers are currently running, and the ports on which they are listening, are maintained in separate databases by each “IMR launcher/monitor” process.
- The “IMR point of contact” process might not maintain a database at all. Instead, all the information about the servers that run on a particular host is held in a database that is maintained by the “IMR launcher/monitor” process on that host.
These variations are relatively minor implementation details, and do not have any impact on the quality of service offered by a CORBA product.
CORBA products usually do not place any restriction on how many or how few IMRs you can create and whether different IMRs run on the same or different computers. Rather, the choice of the number of IMRs installed in an organization is typically due to pragmatic considerations. For example, it is common for each developer to have his or her own “private” IMR for day-to-day development work. Another IMR might be used for system testing, and yet another IMR might be used for deployed applications. An organization might find it convenient to have several “deployment” IMRs: perhaps a separate one for each branch or department in the organization, or perhaps one IMR for payroll applications and another IMR for stock-control applications. Obviously, if there are several IMRs running on the same computer then they need to listen on different ports. Typically, environment variables, configuration files or command-line arguments passed to a server are used to specify the host and port for the IMR that controls it.
7.3 Examples of Implementation Repositories
The following subsections give a brief overview of the IMRs in several CORBA products.
7.3.1 Orbix
The Orbix IMR is a distributed IMR, like that shown in Figure 7.4:
- The Orbix name for the “IMR point of contact” is the locator daemon (itlocator).5 Orbix calls this process a locator because it helps clients to locate (objects in) server processes. The Orbix name for the “IMR launcher/monitor” is the node daemon (itnode_daemon). 6 It is called this because there is one of these processes on each node (computer) where server processes can be deployed through the IMR.
- The itadmin utility is a command-line-driven CORBA client that communicates with the locator daemon to query and update the IMR database. In effect, itadmin performs the work of the hypothetical reg_srv_with_imr utility discussed earlier in this chapter. A lot of Orbix administration is performed through various sub-commands of this utility. When a server application is registered with the IMR, one piece of registration information specifies the node daemon (computer) that should be used for launching the server.
- In older versions of Orbix, the node daemon used to “ping” servers periodically to check if they were still alive. In more modern versions of Orbix, there is an open socket connection between the node daemon and a server process; when this socket connection closes, the node daemon realizes that a server has died.
When a server is being registered with the IMR, it can actually be registered as a replicated server that can be run on several different computers. The IMR keeps track of which server replicas are currently running, and can re-launch replicas that have crashed. The IMR can use a round-robin or random policy to redirect clients to server replicas. In this way, a per-client load-balancing mechanism is provided by the Orbix IMR without any need for extra coding in either client or server applications.
The Orbix IMR (and other other important pieces of infrastructure, such as the Naming Service) can be replicated on several computers. Doing this avoids single points of failure.
You create an Orbix IMR by running the itconfigure utility (which is discussed in the Orbix Administrator’s Guide). You should note that implementation repository is the official CORBA terminology, but it is common for CORBA vendors to invent their own names for their IMRs. For example, the Orbix name for an IMR is a location domain. A location domain is simply the contents of the IMR database—that is, the details of all registered server applications—plus the locator daemon and its supporting node daemon(s).
7.3.2 Orbacus
The Orbacus IMR is a distributed IMR, like that shown in Figure 7.4:
- The functionality of both the “IMR point of contact” and “IMR launcher/monitor” are embedded in a single executable called imr. In Orbacus terminology, the “IMR launcher/monitor” capability is referred to as the object activation daemon (OAD). By default, the imr executable enables both the “IMR point of contact” and the OAD functionality; the -master command-line option instructs it to enable just the “IMR point of contact” functionality, and the -slave command-line option instructs it to enable just the OAD functionality. If you want to have server applications running on several computers all controlled by a single IMR then start the imr executable on all the computers, but use the -master and -slave command-line options to ensure that you have “IMR point of contact” functionality on just one computer and OAD functionality on all the computers.
- The imradmin utility is a command-line-driven CORBA client that communicates with the “IMR point of contact” process to query and update the IMR database. In effect, imradmin performs the work of the hypothetical reg_srv_with_imr utility discussed earlier in this chapter. A lot of Orbacus administration is performed through various sub-commands of this utility.
When you run the Orbacus IMR for the first time, it creates and initializes its database. The Orbacus IMR cannot be replicated. Because of this, it is a single point of failure, which may be unacceptable in some organizations. Neither does Orbacus provide support for registering a replicated server with the IMR.
7.3.3 TAO
Up until and including version 1.2, the TAO IMR was a monolithic IMR. However, version 1.3 saw the start of work to turn the monolithic IMR into a distributed IMR, like that shown in Figure 7.4. This work is still ongoing. In particular, the functionality of the IMR has been split into two executables—ImplRepo_Service (the “IMR point of contact”) and ImR_Activator (the “IMR launcher/monitor”). However, in versions 1.3 and 1.4, both of these processes must run on the same computer: support has not been added (yet) for one ImplRepo_Service to delegate to an ImR_Activator running on another computer.
The tao_imr utility is a command-line-driven CORBA client that communicates with the “IMR point of contact” process to query and update the IMR database. In effect, tao_imr performs the work of the hypothetical reg_srv_with_imr utility discussed earlier in this chapter. A lot of TAO administration is performed through various sub-commands of this utility.
When you run the TAO IMR for the first time, it creates and initializes its database. The TAO IMR cannot be replicated. Because of this, it is a single point of failure, which may be unacceptable in some organizations. Neither does TAO provide support for per-client load balancing by registering a replicated server with the IMR.
7.4 Comparison of Different IMRs
The discussion in Section 7.3 indicates some similarities and differences between the Orbix, Orbacus and TAO IMRs. It is worthwhile highlighting these, because there are likely to be similar likenesses and differences with the IMRs of other CORBA products:
- Each CORBA product tends to use its own terminology for the implementation repository. For example, Orbix uses the terms locator daemon and node daemon, while Orbacus uses the terms IMR and OAD. Such differences in terminology are confusing for many people.
- Some early CORBA products implemented the IMR as a monolithic process. However, it is common for modern CORBA products to split the IMR functionality into two separate applications, as illustrated in Figure 7.4.
- Some CORBA products have built-in replication infrastructure that allows the IMR to be replicated and also optionally allows server applications to be replicated. This replication capability can be used to avoid single points of failure in a deployed CORBA system, and may also provide per-client load balancing capabilities. Alternative replication mechanisms are discussed in Chapters 17 and 18.
- 1
- Most/all CORBA products have a proprietary command-line option or entry in a configuration file that can be used to instruct a server process to listen on a specific port. However, the discussion in this chapter assumes that the server listens on a random port. A discussion about different ways to deploy CORBA servers can be found in Chapter 8.
- 2
- This discussion is applicable only to references for persistent objects. The distinction between persistent and transient objects is discussed in Sections 6.1.3 and 8.2.2.
- 3
- Variations on this scheme exist. For example, Orbix 6 does not embed a server name in an object key. However, a prefix (specified in a configuration file) may be attached to the name of a POA, and this prefix is embedded in the object key. Many people set the prefix to be the server’s name, so the effect is as if the server’s name was embedded in the object key.
- 4
- The CORBA specification explicitly requires a CORBA implementation to ensure that there is no namespace pollution of POA names across different server applications. Despite this, at least one implementation of CORBA neglects to embed a server name into object keys of persistent objects. This causes a scalability problem in the IMRs of such CORBA products, as it is not possible for a single IMR to deploy several servers that have similarly-named POAs. If you intend to deploy several servers through one IMR then check that your CORBA vendor’s product does not suffer from this problem.
- 5
- Many executables supplied with Orbix start with the prefix "it". This prefix is an acronym for IONA Technologies, and is used to prevent namespace pollution of executables installed on a computer.
- 6
- The node daemon was called the activation daemon in older versions of Orbix.